Conforme o descrito nos artigos que apresentaram como utilizar-se do recurso de criação de perfis de monitoração (templates) para acelerar e padronizar o seu ambiente, apresentamos agora artigo versando sobre como construir seus próprios processos de autodescoberta interna (Low Level Discovery – LLD).
O processo do LLD funciona de uma forma muito simples:
- É executado contra o agente do zabbix uma consulta a um parâmetro (neste exemplo o meulld);
- O retorno desta consulta é um código no formato JSON ;
- Com base no resultado da consulta são gerados N itens, N triggers e N gráficos no host;
Sim, ao contrário do que uma primeira leitura à documentação do Zabbix pode indicar… fazer um LLD é muito simples mesmo. Vamos comprovar isso construindo um script PHP e um script BASH para fazer uma descoberta automática de todas as tabelas de um banco de dados e criar itens de coleta para guardar a quantidade de registros em cada um (um exercício simples para demonstrar como fazer um LLD customizado).
Os arquivos utilizados neste exemplo estão disponíveis aqui (no GITHUB). Ao final deste artigo eu irei dizer como instala-los caso você opte por não cria-los (não recomendo pois a ideia é de exercitar o método… só o arquivo .php que é interessante copiar devido a existência de funções adicionais para acesso ao banco).
Baixe o pacote e expanda os arquivos. Na sequência crie uma pasta chamada extras dentro do diretório da interface web do seu zabbix (frontend). As linhas abaixo exemplificam como você pode fazer isso considerando que o seu frontend esteja instalado em /var/www.
mkdir /var/www/extras wget https://github.com/SpawW/zabbix-templates/archive/master.zip unzip master.zip cp -Rpv "zabbix-templates-master/800 - LLD/Exemplos/Descoberta de Tabelas/lldBasesMySQL.php" /var/www/extras/
Vou começar explicando a parte relacionada ao “objetivo pretendido” do script PHP que fiz para este exemplo. Este script irá aproveitar-se do mesmo arquivo de configuração da interface web do Zabbix (afinal é um exemplo) para recuperar as credenciais de autenticação com o banco de dados, listar todas as tabelas e retorna-las em formato JSON. A parte útil (relativa diretamente ao propósito) do script é detalhada abaixo:
if ($_REQUEST['p_acao'] == "LLD") {
$dados = arraySelect('show tables');
foreach ($dados as $linha) {
$json[count($json)]['{#NOME}'] = $linha['Tables_in_zabbix'];
}
echo json_encode(array('data'=>$json));
}
if ($_REQUEST['p_acao'] == "count") {
echo valorCampo('select count(*) as id from '.$_REQUEST['p_tabela'], 'id');
}
Caso o parâmetro p_acao receba o valor LLD o script PHP consulta o banco de dados mysql, trata os dados retornando e transformando tudo em um array padronizado onde cada nome de tabela está dentro de uma tag {#NOME}, agrupo todo o resultado em um array nomado “data” e uso a função nativa do PHP json_encode para gerar o código JSON.
Caso o parâmetro p_acao receba o valor count o script PHP irá retornar a quantidade de linhas da tabela definida no parâmetro p_tabela.
A função arraySelect é uma função genérica que criei para buscar o resultado de uma consulta ao banco de dados mysql formatando o resultado em um array padrão php. A função jsonEncode transforma um array padrão do php em um array no formato json (requisito obrigatório para que o zabbix consiga processar o LLD).
Uma vez que foram explicadas as funcionalidades e as principais funções do script php (lembrando que ele é um exemplo… é o gerador de dados… você irá fazer algo muito mais útil que este meu exemplo com certeza 😉 ) vamos configurar ao agente do Zabbix como utilizar este script. Isso será feito através do recurso de UserParameter.
Poderíamos adicionar uma linha com um wget ou um curl que iria funcionar, entretanto, esta não é uma boa prática pois a cada nova funcionalidade que você queira adicionar à sua monitoração você terá que alterar este arquivo em cada servidor e reiniciar o agente. O Zabbix suporta que você indique um caminho para o agente carregar automaticamente qualquer configuração lá existente, vamos adotar esta abordagem. Altere o arquivo /usr/local/etc/zabbix_agentd.conf removendo o comentário (#) da linha abaixo.
Include=/usr/local/etc/zabbix_agentd.conf.d/
Eu adoto como uma boa prática ter um arquivo .conf para cada kit de parâmetros. Se eu crio scripts (bash, php, seja o que for…) para monitorar determinada aplicação ou serviço eu crio também um arquivo .conf específico para que o Zabbix saiba como requisitar as informações. Entendo que trabalhar desta forma facilita a instalação dos scripts em ambientes heterogêneos.
Crie o arquivo zalld.conf em /usr/local/etc/zabbix_agentd.conf.d/ com o conteúdo abaixo:
UserParameter=meulld[*],/usr/local/share/zabbix/externalscripts/zalld.sh $1 $2 $3
Salve o arquivo e se certifique que o mesmo está configurado de forma que o proprietário e grupo sejam do zabbix. Neste momento o agente reconhece uma nova chave “meulld” que aceita inclusive que se passem parâmetros.
Vamos agora criar o script bash que irá ser responsável por chamar a página feita em php. Por quê fazer um script bash e um em PHP ?
1) Fazer as consultas ao banco de dados em php é mais simples.
2) Fazer os testes no shell é mais simples através de um script bash.
3) Eu não preciso reiniciar o agente várias vezes enquanto estou desenvolvendo.
Crie o arquivo /usr/local/share/zabbix/externalscripts/zalld.sh com o conteúdo abaixo:
#! /bin/bash
#
# Name: zalld
#
# Custom LLD Sample.
#
# Author: Adail Horst
#
# Version: 1.0
#
zaver="1.0"
rval=0
########
# Main #
########
#set -x
OPCAO=$1;
case $OPCAO in
'LLD')
curl http://localhost/extras/lldBasesMySQL.php?p_acao=LLD;
;;
'count')
curl "http://localhost/extras/lldBasesMySQL.php?p_acao=count&p_tabela=$2";
;;
esac
exit $rval
#
# end
Como pode-se observar este script aceita dois parâmetros:
1) Tipo da operação a ser realizada;
2) Se o tipo da operação for “count” o script requer um parâmetro adicional com o nome da tabela.
Em ambos os casos o script simplesmente irá executar um comando curl e retornará o resultado para o Zabbix. Simples assim.
Vamos testar se está tudo funcionando corretamente. Primeiramente vamos validar em modo texto se o script está funcional. Execute o comando abaixo:
zabbix_get -s127.0.0.1 -k'meulld[LLD]'
O resultado apresentado deverá ser um texto começando com o exemplo abaixo:
{"data":[{"{#NOME}":"acknowledges"},{"{#NOME}":"actions"},{"{#NOME}":"alerts"},{"{#NOME}":"applications"},{"{#NOME}":"auditlog"},{"{#NOME}":"auditlog_details"},{"{#NOME}":"autoreg_host"},{"{#NOME}":"conditions"},{"{#NOME}":"config"},{"{#NOME}":"dchecks"},{"{#NOME}":"dhosts"},{"{#NOME}":"drules"},{"{#NOME}":"dservices"},{"{#NOME}":"escalations"},{"{#NOME}":"events"},{"{#NOME}":"expressions"},{"{#NOME}":"functions"},{"{#NOME}":"globalmacro"},{"{#NOME}":"globalvars"},{"{#NOME}":"graph_discovery"},{"{#NOME}":"graph_theme"},{"{#NOME}":"graphs"},{"{#NOME}":"graphs_items"},{"{#NOME}":"groups"}...
Observemos aí a arquitetura que você deverá sempre construir quando quiser construir um LLD: um array nomeado em formato JSON!
Observem como é o resultado da consulta à chave padrão do Zabbix para descoberta de interfaces:
zabbix_get -s127.0.0.1 -k'net.if.discovery'
{
"data":[
{
"{#IFNAME}":"lo"},
{
"{#IFNAME}":"eth0"},
{
"{#IFNAME}":"eth1"}]}
Observem que a estrutura é a mesma (ta bom… a Zabbix INC teve o trabalho de identar o resultado e deixar mais bonitinho…). Mudam apenas duas coisas: O nome da “variável” e o valor descoberto para cada ocorrência de interface.
Vamos testar agora e ver um exemplo de descoberta de sistema de arquivos ?
zabbix_get -s127.0.0.1 -k'vfs.fs.discovery'
{
"data":[
{
"{#FSNAME}":"\/",
"{#FSTYPE}":"rootfs"},
{
"{#FSNAME}":"\/sys",
"{#FSTYPE}":"sysfs"},
{
"{#FSNAME}":"\/proc",
"{#FSTYPE}":"proc"},
...
Aqui constatamos mais outra coisa que é muito interessante: não é limitado à uma variável sendo retornada… podemos retornar dois valores para cada sistema de arquivos descoberto ! Neste caso é retornado o nome e o tipo do sistema de arquivos.
Então se precisar retornar um índice, um nome, um valor e um estado para cada item descoberto… pode Arnaldo? Pooooode. 🙂
Uma vez que temos toda a parte de scripts criada e validada vamos a parte de configuração da regra de descoberta no host pois o agente Zabbix já sabe como fazer a descoberta mas o servidor Zabbix ainda não sabe que existe este novo método de descoberta que você criou.
Acesse o Zabbix e crie um host apontando para 127.0.0.1 com interface do tipo Agente Zabbix.
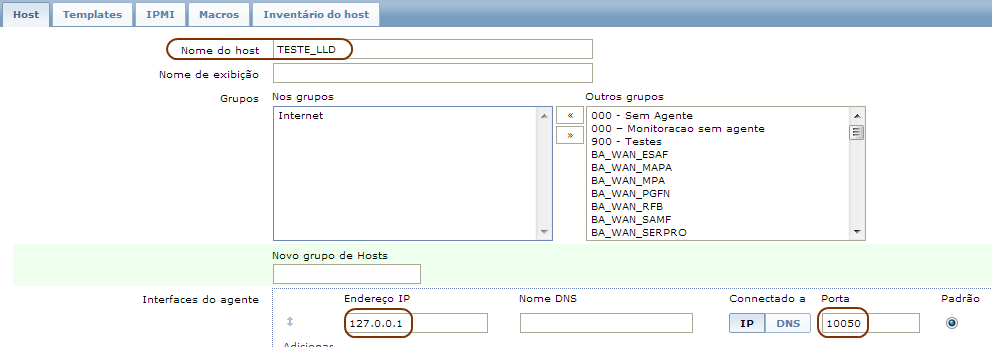
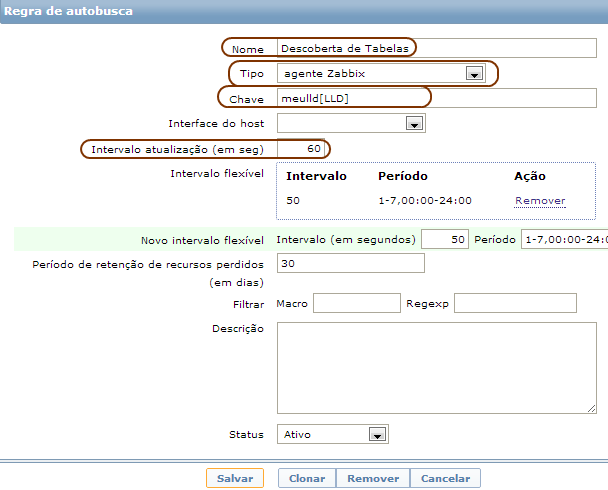
Clique no link Autobusca da linha do host que você acabou de adicionar (TESTE_LLD). Após a lista de regras de descoberta ser apresentada clique no botão “Criar Regra de Descoberta” situado no canto superior direito da tela. Preencha o formulário conforme definições abaixo e salve o registro.
| Propriedade | Valor |
| Nome | Descoberta de Tabelas |
| Chave | meulld[LLD] |
| Intervalo de Atualização (em Seg) | 60 |
Como você deve ter percebido, este não é de forma alguma um perfil de descoberta para deixarmos sendo executado em larga escala contra nosso ambiente de produção pois não tem muito sentido ficar descobrindo a cada sessenta segundos os itens.Após o preenchimento o seu formulário deverá estar similar à imagem abaixo.
Vamos agora criar protótipo de item para receber o resultado desta regra de descoberta senão ela fica sem nenhum sentido pois ela não irá gerar nenhum resultado (mesma coisa de um template que não tem nenhum item).
Clique no link “Protótipos de item (0)” e em seguida no botão “Criar Protótipo de Item” e preencha o formulário com as informações abaixo:
| Propriedade | Valor |
| Nome | Total de registros em {#NOME} |
| Chave | meulld[count,{#NOME}] |
| Intervalo de Atualização (em Seg) | 60 |
| Nova Aplicação | Estatísticas de Tabela |
Após salvar você terá o seu protótipo de item criado e bastará aguardar que o processo de descoberta ocorra para verificar os resultados. Observem no meu laboratório quantos itens foram criados por um simples protótipo de item.
![]()
É neste momento que você tem que ficar atento… a criação de itens a partir de protótipos funciona… e funciona bem… para cada elemento descoberto o Zabbix irá criar um item para cada protótipo definido.
O banco de dados do Zabbix 2.0 possui 103 tabelas e você definiu um protótipo de item, logo tem 103 itens após a descoberta.
Espero que após este tutorial você esteja mais a vontade para criar seus próprios processos de descoberta. Muitas vezes um simples script bash pode fazer a descoberta toda…